
LMArena ARR hit $30M in 4 months, How a “Boring” Leaderboard Became a $1.7B AI Infra
The real moat: Network Effects

Many people are building AI leaderboards. Almost none of them are worth $1.7B.
LMArena is. It is a company I find extremely interesting—and one I believe may be undervalued.
Just seven months after raising a $100M seed round, the AI evaluation platform announced a new $150M+ Series A, valuing the company at $1.7B—nearly three times its previous $600M valuation.
The round was co-led by Felicis and UC Investments, with participation from a16z, KP, and Lightspeed.
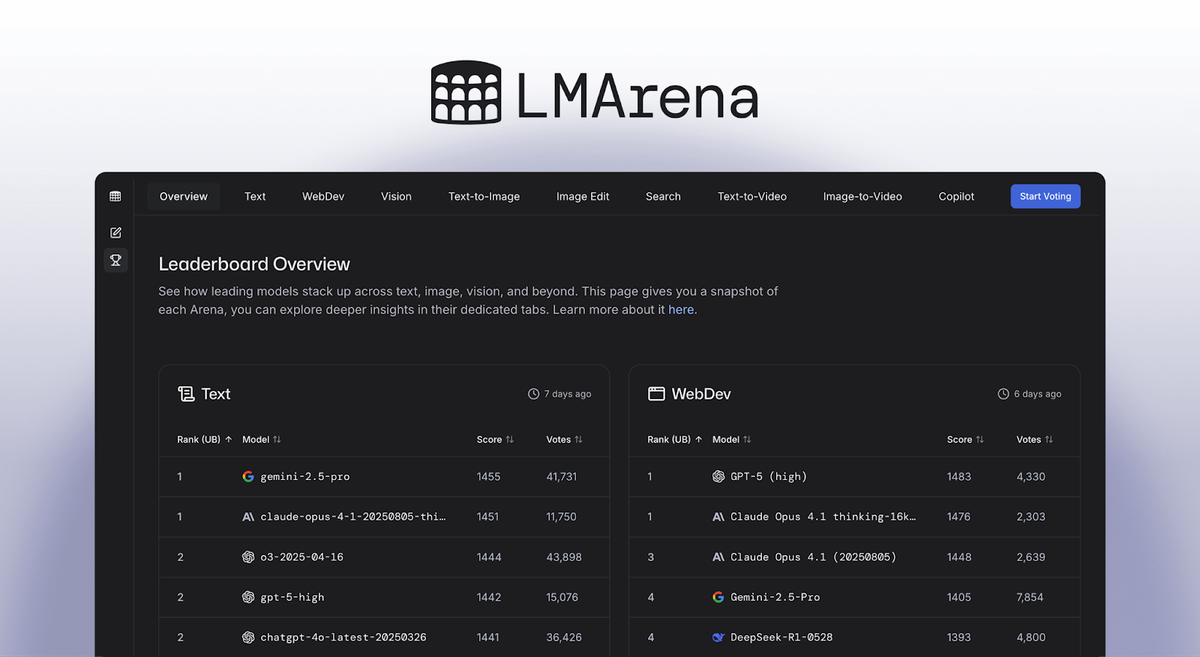
At first glance, LMArena looks deceptively simple. LMArena’s core product, Chatbot Arena: users compare responses from two AI models, vote on which answer is better, and those votes power a public leaderboard.
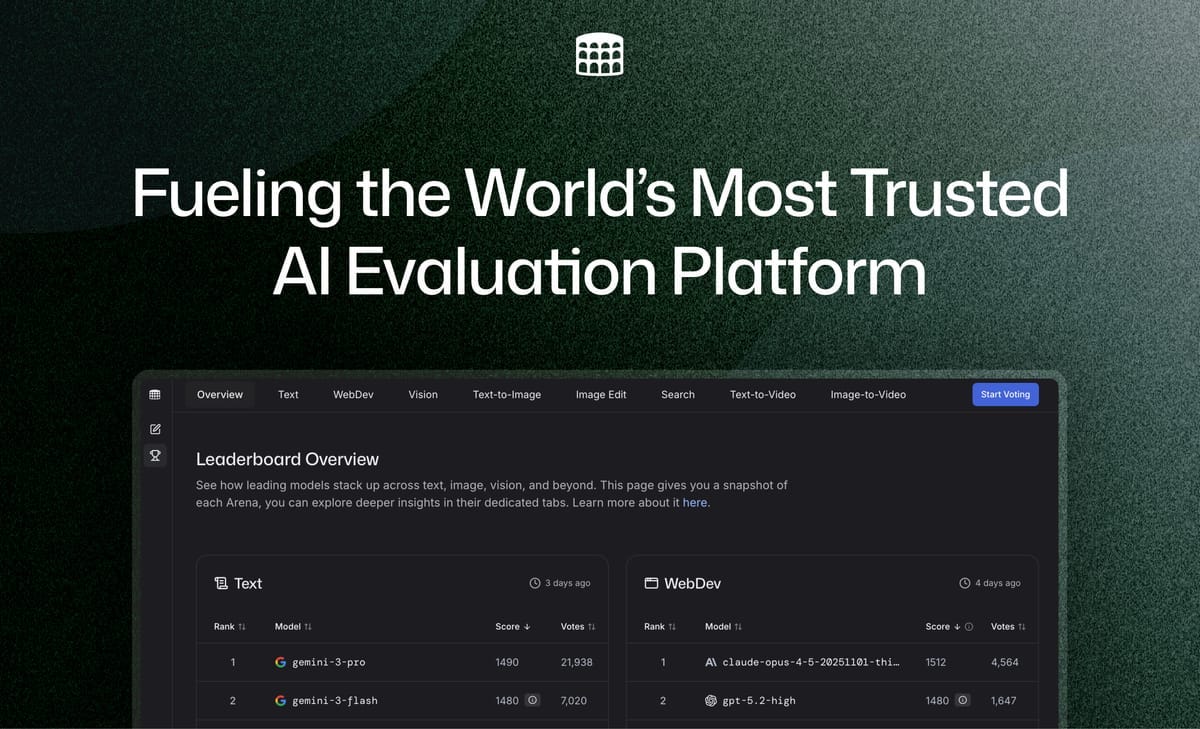
So how does something this simple become one of the most valuable AI infrastructure companies in the world?
The answer lies in scale, timing, and a series of unusually disciplined decisions.
The numbers behind the valuation
Over the past seven months, LMArena has quietly built momentum that few AI startups can match:
25× user growth, reaching 35M+ unique users
Revenue scaled from $0 to nearly $30M ARR in four months
(paid products launched only in September,2025)
50M votes across text, vision, web development, search, video, and image tasks
5M monthly active users across 150+ countries
60M monthly conversations
400+ AI models evaluated
These numbers reframed the conversation. LMArena wasn’t just a leaderboard—it was becoming infrastructure.
The real problem LMArena is solving
When a16z led LMArena’s seed round, they argued that the most valuable AI companies would be the ones that make AI “boring.”
Not uninspiring—reliable, predictable, and trustworthy.
That’s exactly what LMArena is building: a neutral layer that makes AI performance measurable in the real world.
Felicis echoed this in its investment memo. AI models are improving at breakneck speed, but that velocity creates two structural problems:
How do we continuously measure progress across models?
How do we benchmark them in real-world use cases—not synthetic tests?
Static benchmarks can’t keep up. Enterprises and model builders need live, human-driven feedback.
LMArena provides that signal.
From an open-source experiment to a global platform
Chatbot Arena began almost accidentally.
In early 2023, researchers at Berkeley had just released Vicuna, an open-source chatbot. Users wanted to compare it against Stanford’s Alpaca.
So professor Ion Stoica and his students Wei-Lin Chiang and Anastasios Angelopoulos let the two models “battle” head-to-head.
The community loved it.
What started as a simple comparison tool quickly evolved into a platform where any two models could be matched anonymously, with humans voting on the better response.
2 years later, that “fun experiment” had turned into a company that raised $250M and reached $30M ARR just months after monetization.
Ion Stoica: The Architect Behind Multiple Billion-Dollar Platforms
To understand why LMArena worked, and the five decisions that built a moat, you have to understand Ion Stoica.
